










AI-аудиоассистент страницы – интеллектуальный модуль, открывающий возможность прослушивания содержимого страницы в разных режимах. Решение будет интегрировано на вебсайты:
Как инструмент работает на практике?
- система определяет содержание страницы;
- отделяет главный контент от лишних элементов и готовит к дальнейшей обработке;
- формирует сжатое изложение или объяснение с помощью искусственного интеллекта;
- преобразует текст в аудио с помощью TTS.
Решение реализовано в формате компактного виджета с мини-плеером, поддерживающим несколько сценариев взаимодействия – от полного озвучивания страницы до быстрого ознакомления с содержанием или упрощенного объяснения сложных материалов.








Проблема бизнеса
Большинство пользователей не читают длинные страницы – контент сканируется, а не прорабатывается. Объемные тексты, даже если они качественные, теряют внимание уже на первых экранах.
Сложный материал воспринимается еще ужаснее. Темы типа AI, crypto-тематики или профессиональных услуг требуют контекста и объяснения, но в текстовом формате это создает дополнительную нагрузку на читателя. В результате часть содержания просто игнорируется или трактуется неправильно.
Падает и уровень вовлечённости: пользователи не доходят до основных блоков, не погружаются в детали и покидают страницу. Одновременно отсутствует альтернатива тексту – если нет времени или желания читать, взаимодействие с контентом прекращается.
Дополнительно возникает проблема быстрого понимания сущности. Чтобы поймать основную идею страницы, приходится тратить время на просмотр всего материала.
Цель проекта
Основная цель проекта – создать AI-модуль, трансформирующий способ взаимодействия с контентом и расширяющий сценарии его потребления.
Решение ориентировано на то, чтобы:
- предоставить возможность прослушивать содержимое страниц в удобном формате;
- упростить восприятие сложного контента через структурированное изложение и объяснение;
- повысить уровень вовлеченности пользователей и время взаимодействия со страницей.
В фокусе – не отдельная функция, а целостный инструмент, улучшающий доступность информации и делающий контент более понятным вне зависимости от его сложности.
Режимы работы
Модуль поддерживает три сценария использования, каждый из которых соответствует отдельной потребности пользователя – от полного прослушивания страницы до мгновенного понимания содержания или упрощенного пояснения.
Read page
Что происходит:
- определяется текущая страница;
- извлекается основной текст;
- удаляются лишние элементы;
- подготовленный текст передается в TTS;
- воспроизводится аудио.
Режим подходит для полноценного ознакомления со страницами в аудиоформате без потери содержания.
Listen summary by AI
Что происходит:
- извлекается контент страницы;
- передается в LLM для обработки;
- формируется краткое изложение основных тезисов;
- результат посылается в TTS;
- воспроизводится аудио.
Сценарий ориентирован на мгновенное понимание сущности без погружения в детали.
ASK AI to explain this page
Что происходит:
- извлекается контент страницы;
- передается в LLM;
- генерируется объяснение на простом языке;
- результат передается в TTS;
- воспроизводится аудио.
Режим используется для интерпретации сложного контента, когда требуется дополнительное разъяснение и упрощение подачи.
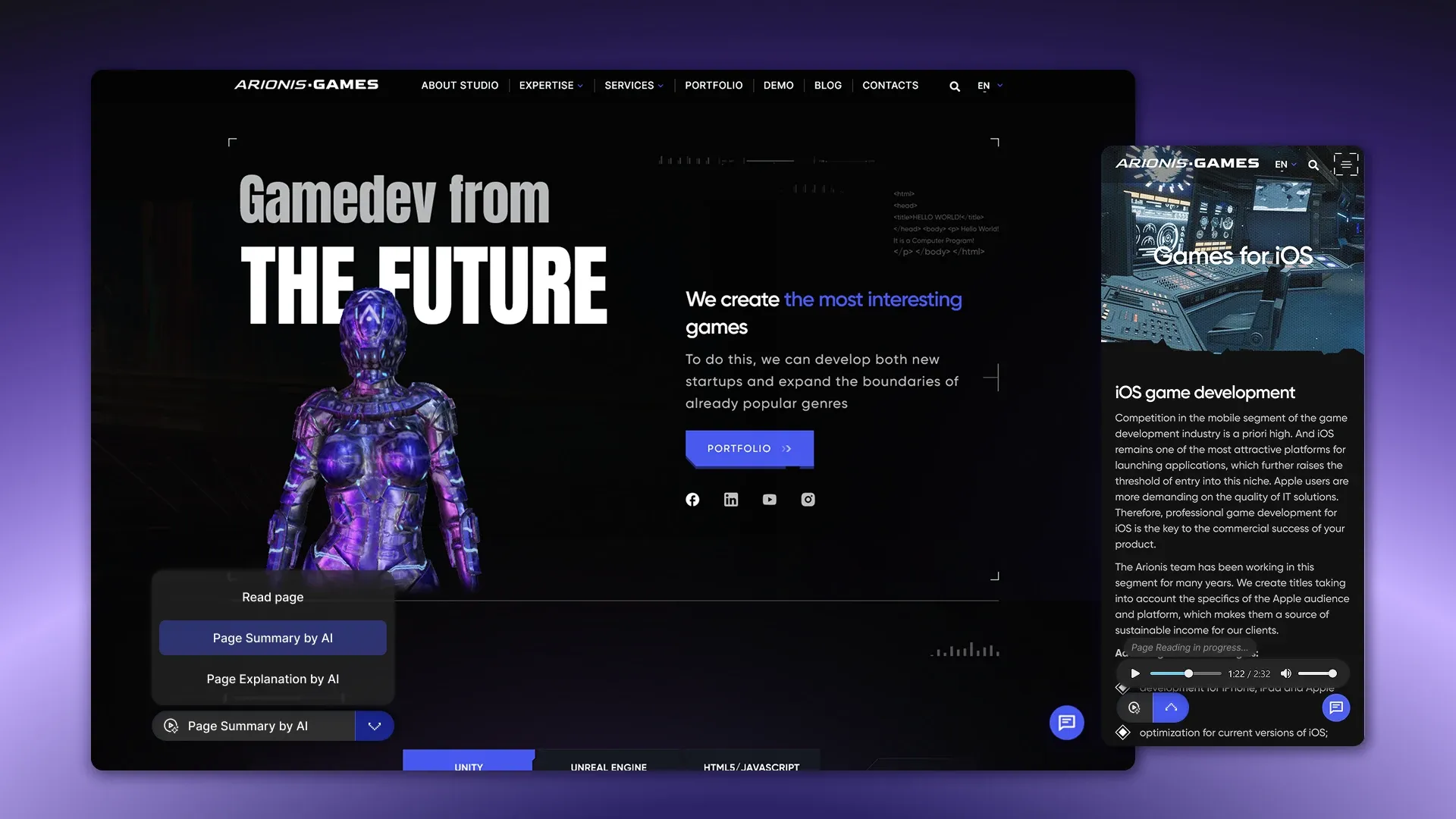
UX интерфейс
Взаимодействие с модулем реализовано через компактный виджет, интегрированный непосредственно в страницу. Кнопка активации находится в видимой зоне интерфейса и открывает доступ ко всем доступным режимам работы.
После запуска пользователь получает список сценариев: озвучивание страницы, краткое изложение или объяснение. Переключение между режимами происходит оперативно и не требует перезагрузки страницы.
Основной элемент интерфейса – мини-плеер, обеспечивающий полный контроль над воспроизведением:
- управление воспроизведением (Play/Pause/Stop);
- индикатор прогресса воспроизведения для навигации по аудио;
- регулировка скорости (1x/1.25x/1.5x);
- отображение текущего времени и продолжительности;
- возможность закрытия плеера.
Дополнительно предусмотрены состояния загрузки, информирующие об обработке запроса, а также отображение общей продолжительности аудио. Для удобства пользователя доступен текстовый транскрипт, который синхронизируется с воспроизведением и позволяет параллельно читать или оперативно находить нужные фрагменты.
Логика извлечения контента
Система работает по четкой схеме, чтобы обеспечить максимально чистое и релевантное содержимое для будущей обработки и озвучки. Она извлекает основной контент страницы, игнорируя служебные элементы, не несущие смысловой нагрузки для пользователя.
Что вытягивается:
- заголовок страницы;
- основной текст;
- структурные секции;
- списки.
Пропускаемый:
- шапка сайта;
- футер;
- навигационное меню;
- всплывающие окна;
- сообщения о куки.
Поток обработки по режимам
Каждый режим модуля имеет четкую цепочку действий, что гарантирует быстрое и надежное получение аудио пользователя.
- Озвучивание страницы: запрос → выделение контента → преобразование в аудио через TTS → кэширование → воспроизведение.
- Краткое изложение АИ: выделение контента → обработка LLM → формирование сжатого изложения → TTS → кэширование.
- Пояснение страницы AI: выделение контента → обработка LLM → генерация объяснения → TTS → кэширование.
Архитектура решения
Фронтенд
- Виджет → интегрируется в страницу, предоставляет доступ ко всем режимам работы и открывает мини-плеер для управления воспроизведением аудио.
- Мини-плеер → отвечает за управление воспроизведением (Play/Pause/Stop), регулировку скорости, показ прогресса и времени, отображение состояния загрузки.
- API вызовы → гарантируют обмен данными между фронтендом и бэкендом, передают параметры страницы, режим работы и настройки воспроизведения.
Бекенд
- Модуль выделения контента → извлекает основной текст страницы, структурные секции и списки, игнорируя вспомогательные элементы.
- AI-обработка → отвечает за генерацию краткого изложения или объяснений простыми словами с помощью LLM.
- Модуль TTS → преобразует текстовый контент в аудио.
- Кэширование → сохраняет результаты выделения контента, обзора, пояснений и аудио для повторного воспроизведения.
Наружные сервисы
- ElevenLabs → отвечает за синтез естественной речи.
- OpenAI → обеспечивает генерацию кратких изложений и пояснений через большие языковые модели.

Кэширование
Для ускорения работы модуля и экономии ресурсов предусмотрено сохранение обработанных данных в кэше. Это позволяет снова использовать результаты без повторной обработки одних и тех же страниц.
Что хранится в кэше:
- контент страницы;
- сжатое изложение;
- объяснение страницы;
- аудио.
Ошибки и механизм восстановления
Система подразумевает обработку возможных сбоев для обеспечения непрерывного пользовательского опыта.
- Если обработка контента через LLM не удалась, модуль автоматически переходит в режим озвучивания страницы, чтобы пользователь мог прослушать хотя бы базовый текст.
- В случае ошибки TTS пользователь получает уведомление о невозможности воспроизведения аудио.
- Если на странице нет контента, воспроизведение не запускается, и модуль остается в неактивном состоянии.
Аналитика
Для оценки эффективности AI-аудиоассистента страницы предусмотрен сбор и анализ основных показателей взаимодействия пользователей с модулем. Такой подход помогает понимать, какие режимы наиболее востребованы и как хорошо воспринимается контент.
- Запуск по режимам – фиксируется, какой из трех режимов (озвучение страницы, краткое изложение, объяснение) активирует пользователь. Позволяет определить приоритетные сценарии использования и оптимизировать UX.
- Продолжительность прослушивания – отслеживается время, в течение которого пользователь слушает аудио. Этот показатель показывает, насколько контент интересен и задерживает внимание.
- Процент дослушивания – отображает часть аудио, которую пользователь фактически прослушал от начала до конца. Помогает оценить, насколько полно человек воспринимает материал и где возникает потеря внимания.
- Популярные страницы – аналитика собирает данные о том, какие страницы пользователи чаще всего прослушивают. Таким образом, можно выделить наиболее востребованный контент и корректировать стратегию подачи материалов.

Технологический стек
- OpenAI (LLM) – используется для обработки текста, генерации кратких изложений и объяснений простыми словами.
- ElevenLabs (TTS) – отвечает за синтез естественной речи и создание аудио высокого качества.
- Node.js / Python (бэкенд) – гарантируют логику обработки контента, AI-процессов, взаимодействия с базами данных и внешними сервисами.
- React / JavaScript (фронтенд) – отвечают за виджет на странице, мини-плеер, управление режимами и интерактивный UX.
- S3/storage – служит для хранения аудио и текстовых результатов обработки, предоставляя доступность и надежность данных.
- Redis/cache – используется для кэширования контента, сжатых изложений, пояснений и аудио. Так ускоряется повторное воспроизведение и уменьшается нагрузка на систему.
Результат
Внедрение AI-аудиоассистента страницы стало стратегическим шагом для повышения эффективности взаимодействия пользователей с контентом на сайтах и цифровых сервисах. Уникальный модуль обеспечивает комплексную автоматизацию озвучки, краткого изложения и пояснений, что существенно изменяет способ потребления информации. Модуль легко интегрируется на любой сайт, в приложение или сервис, подстраиваясь под разные платформы и потребности бизнеса.
Бизнес-эффект внедрения
- Рост вовлечённости: пользователи активно взаимодействуют со страницами, переключаются между режимами и дослушивают аудио до конца.
- Увеличение времени на странице: аудио и интерактивные объяснения мотивируют оставаться дольше и глубже прорабатывать материал.
- Улучшение понимания контента: сложные страницы (AI, SaaS, услуги) становятся доступными благодаря краткому изложению и объяснения на простом языке.
Хотите добавить AI-аудиоассистента на свой сайт?
Проанализируем ваш контент, предложим оптимальную логику работы и внедрим модуль под задачи вашего продукта – от MVP до production. Оставьте заявку – обсудим ваш кейс.